
Automating Myself Out of Development - part2
I overshot and got into self-doubt spiral

I had a hard time finishing this article to be honest. I couldn’t understand myself if what I was building is the right way or not. And so I sat on it for too long and forgot a lot of implementation details. So this one is going to be a bit messier, but there’s some “kern” in it, so if you will, bear with me, and let’s figure things out together.
What helped me get out of the state of dread and actually finish it were two things
a) the conversation with Ia - she said something along the lines “we suddenly stopped being part of development with AI, but then we realized that we can build systems around AI to create code”. and
b) Adrian’s book “Why We Still Suck at Resilience” - and I’ll tell you how in the end.
But let’s get to it in order. In my last article I walked with you through moving my Claude Code development away from my local machine and into an ec2 instance, writing a skill that can brainstorm/plan/implement the way I want it to, putting a few cron daemons in front of it so features could get specced, planned and implemented overnight against GitHub issues. The state machine lived in issue labels. I touched it five times per feature - all of them either editing a file or flipping a label.
Learning from change
What I actually forgot to tell you, because the article was getting too long as is, is that I also wanted to make it “self-learning” (don’t get agitated, I know it’s not really LEARNING, and I will write about that soon as well) from differences between the spec it created and the version of the spec I really wanted. So Claude code would create the initial spec, I’d review and correct it, and somewhere in one of those daemons I asked it to “compare” the two versions and suggest what kind of information is worth “storing in memory” for the next time.
Modifying a file and then asking LLM to diff-and-learn-from-it feels SO CLUNKY I can’t believe I did that. One comment from Lina snapped me out of it - she mentioned communicating through comments, assigning the task back and waiting for the output - and of course that feels way easier, than modifying the file created and then hoping it’ll get the diff right. The thing is, I forced it to try to reconstruct my intent from a diff, instead of telling it my intent.
So I changed that part - which also simplified my daemons to be honest. I so love when something I do for an unrelated reason, affects another part - this means there was a coupling between those two things in the first place and I just added the right component that would support both.
Here’s how it went: I first created the handler for when I need changes in the spec. If the issue was in the state “spec:needs-review” and I added the “claude:work” and commented something about what I didn’t like in the spec, the daemon would handle it with “revise-spec” handler, which would eventually develop its own complexity. Then I realized that sometimes I had questions, sometimes I had answers...so I added a categorizer of comments. Here’s what it does now:
classify what I wrote in the comment as question or directive
answers the question OR finds the place in the spec that this directive is addressing (e.g. there were OPEN QUESTIONS in the original spec that claude created and I answer with Q1: do X instead of Y) and edit the spec if needed
evaluate if it’s worth saving “that” (the question it had, my answer, the consequences of it) into the memory
log log log everything it’s doing
Learning, redone
So now it suggests learning based on my comments, not the diff between spec-as-AI-imagined it and spec-as-I-corrected-it.
No auto-learning though. Suggest in comments and let me react to it - if I like it, the next invocation of the daemon takes that into account and stores in memory. I can tell you now, half of what it suggest to save as learning was either too specific, or too dangerous to save - so review and discard for sure.
Here are some details if you want:
After any kickback cycle, if the deltas look generalizable, the bot posts a sentineled comment:
📚 Captured learning candidate
Rule: <one sentence>
Why: <reason taken from the human's deltas>
How to apply: <when this kicks in>
👍 = save · 👎 = discard · edit before reacting for a partial save · 7d no react = drop
daemon/lib/learning.sh polls the reactions API on that comment:
👍 writes the rule directly to
brainstorm-memory/principles.md- no.proposed, no graduation step. The 👍 is the curation. It also writes afeedback_kb_<slug>.mdinto auto-memory and adds the index line.👎 hashes the rule into
state.json.kickback.rejected_learningsso the same proposal can’t come back.Edit-then-👍 supports partial saves - the reactions API is independent of the comment body, and the handler re-reads the post-edit text, tolerating a missing
Why:orHow to apply:line.No reaction for seven days and it drops.
Expanding to All Steps
Why not control everything with comment? If I don’t like the plan - I comment, if I notice a bug after implementation - I comment. So now I have similar handles for when the issue is in “plan:draft” and I ask it to modify something, or if it’s already implemented - and I ask it to modify something in the comments. Even for one that was already in the “merged” state and commenting meant - it’s time to open a fresh branch and do some bugfix.
Now I had “one daemon to rule them all” (well, one to handle everything that happens after the enhancement and the spec creation), and the daemon would react to one label “claude:work” and the comment I left with the correct “handler”, depending on which state the issue was at the time of the comment
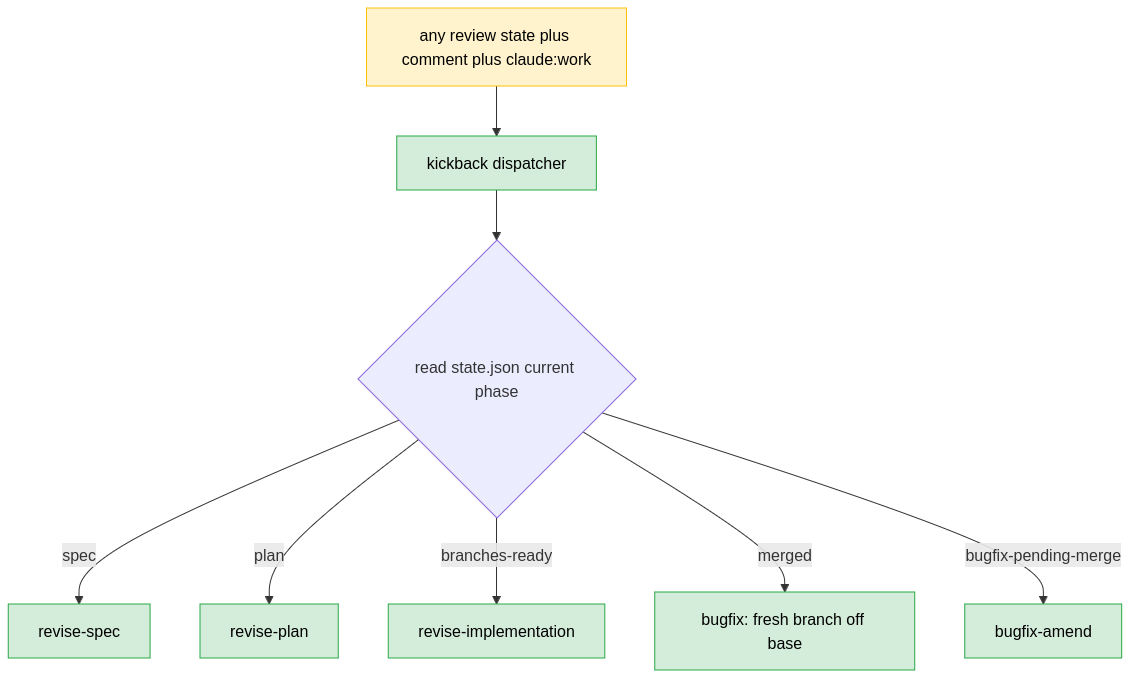
A good tip from Lina - don’t forget to add safety guards towards claude-reacting-to-claude’s comments (you know, I keep saying claude/AI/LLM - interchagneabley, all of this really applies to any “agentic development” I think. Though I tried it with claude code only so...at your own disgression)
The bot/human disambiguation is deliberately paranoid, because the one thing I cannot allow is the model reading its own prose as an instruction. Every bot comment starts with a <!-- ow-bot v1 --> sentinel (daemon/lib/comment.sh), and state.json keeps a last_processed_comment_id cursor. The dispatcher only ever feeds the handler human-authored comments newer than the cursor. Two independent defenses: even if someone strips the sentinel, the cursor stops re-processing.
The crisis (you knew it was coming)
And here’s where you’d stop me and say: hang on. Aren’t you back to having exactly the same conversation with the agent - except instead of a chat window you now have a GitHub ticket?
To be honest, I asked myself the same thing, and for a second there I was about to spiral into a full episode of I wasted weeks, I’m useless, this is all useless, I hate it.
Two things happened. First, I had a croissant and a cup of coffee, and the world got a bit brighter - I recommend this step, it’s underrated and not in any of the diagrams. Second, I started reading “Why We Still Suck at Resilience”.
I noticed what I’d actually built without quite meaning to: a traceable set of specs and cycles that the agent can read and that I can read to learn what’s going wrong in my own process. Editing the spec had given me an illusion of control. The comments gave me something better - a trace. And you should not underestimate traces.
To make the trace real instead of implied, every kickback cycle now writes structured files instead of leaving me to reconstruct history from commit messages and a long issue thread:
specs/issue-N/cycles/cycle-K.md- per cycle: date, the trigger comment URL, each applied directive with a[@user comment](url)back-link per section, open TODOs, and the learning-proposal URL.specs/issue-N/cycles.md- an index regenerated each cycle fromstate.json.kickback.cycle_log.
Both are committed by the dispatcher, and the permalink to the cycle file goes into the issue’s summary comment. Months from now I can pattern-match my own corrections across thirty issues and notice “oh, I keep saying the same thing about CDK.” A chat history can’t do that for me; I can barely find what I said twenty turns ago in one.
When I go through THIS pipeline (and I realized it still needs so much work and improvement), I have ARTIFACTS. Each step has them(spec, plan, comments for spec, cycle logs for them, ...), and hence each step can be improved independently.
By the way, the enhancement phase now, the one that was supposed to prep ticket for spec creation, now looks into the previously SUCCESSFULLY implemented specs to find “related” things we worked on and use those, or rather, take them into consideration.
The Similarity to IaaC
Nowadays nobody questions the value of IaaC (I hope?..), but there were times, people would say “well, it’s faster to do it through console”. Honestly, that ALWAYS felt...”dirty” - like you would pollute that wonderfully clean AWS account with your HANDS. Ok, that’s another story. My point is - yes, I’m faster if it’s a Claude Code console open and we’re going back and forth. BUT - there’s now learning in it. I mean there is, but it’s very easy to ignore it, loose it, forget it. There’s no processing of signal in it. There’s no continuous improvement in it. I’m not even talking about then TEAM dynamics. How talking to Claude is SOLO activity and with pipelines/workflows like this you achieve team alignment.
I Overshot
Remember I told you I’ll overshoot and learn from it?.. Well, I did. I gave it too big of a task, which I was dreading to implement. It was too big. I knew it. I knew I need to research and prep for it first. I knew it! And still, I said, well, let me see if this AUTO-brainstorm-create-spec-create-plan will work. And I wasn’t attentive on those artifacts. Yes, shoot me. I’m human afterall. Anyways. For the last two weeks (two weeks, Carl) I’ve been fixing the results of that disastrous activity. I’ve been cleaning up what it claimed to implement. I’ve been asking it to explain again to me how it works. Eventually I sit down and fixed the architecture. And yeah. Learned to again trust my gut. If it feels too big to delegate to AI completely IT PROBABLY IS!
What Resilience Engineering is Teaching Me
I’ve been reading Adrian’s book on resilience engineering, and it is quietly reshaping how I think about all of this. The thing it gave me is permission to stop chasing a fantasy: I am never going to build the perfect automated implementation flow. I’m gonna say it again THERE IS NO WAY one builds a flow that works PERFECTLY. There isn’t one. Systems like this don’t get finished; they get compensated - you keep adapting them as the world shifts under them.
The point is, and I can actually formulate this now thanks to Adrian’s book: treat every occurrence of me needing to set “claude:work” as a signal that something went south and a chance to learn from it.
BUT as I said my agent cannot learn (at least there’s nothing like “live update weights” as fast as I know.... That would be “learning”). It can follow instructions, and it can be handed more context - that’s what the principles file and the cycles and the enriched issue bodies really are: better instructions and more context.
But it does not learn. I learn. I’m the one who notices that this particular task was too big to hand over in one piece, or that the repo wasn’t actually ready for the feature I threw at it. The lesson is mine, and the traces exist so that I can.
Why didn’t I read about resilience philosophy when I was endlessly trying to create THE PERFECT CI/CD pipeline. It’s the same here. There is no perfect. There is no perfect automation. There’s only continuous learning.
I've invested so much in dark factory patterns, sets of skills, rust based orchestration and routing, allium spec-driven intents, deterministic oracles with mutation-kill. I feel the same way you do. The quality has gone up and up, but the cognitive load has as well. I work on very complex sprawling systems, with loads of integration points and signals/emits, hard AI problems. I've invested in twin DGX Sparks and M4 Max MBP, large screens. I move faster but I do tire. I find the first 4 hours each day are by best. By 4pm it's downhill, lol
Great post, thank you!